Linux is an open-source operating system that is loved by millions of developers worldwide. It provides a powerful command-line interface that allows users to manage their systems effectively. Today, we'll explore some of these essential commands: `#date`, `#uname`, `#hostname`, `#hostid`, `#arch`, and `#nproc`.
The #date Command
The `#date` command in Linux is used to display or set the system date and time. With various formatting options available, users can customize the output to their preference. For instance, `date +"%D-%T"` will display the date and time in the format MM/DD/YY-hh:mm:ss.
The #uname Command
The `#uname` command stands for Unix Name. It displays important information about the system, such as the operating system name, kernel version, and hardware details. Running `uname -a` will provide a comprehensive summary of system information.
The #hostname Command
The `#hostname` command is used to display or set the system's host name. In a network, the hostname is used to identify machines. Simply typing `hostname` in the terminal will display the current hostname, while `hostname new_name` will change the hostname to "new_name".
The #hostid Command
In Linux, the `#hostid` command prints the unique identifier (in hexadecimal format) for the current host. This could be used in network setups for different purposes, including troubleshooting.
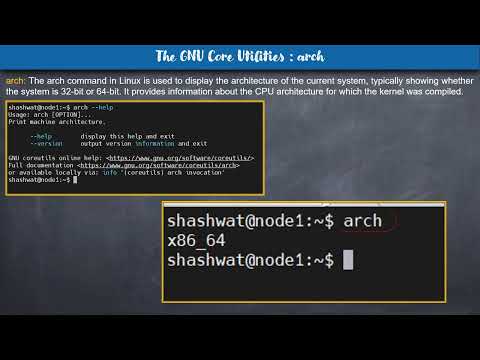
The #arch Command
The `#arch` command is used to display the machine's architecture. It shows whether your machine is running a 32-bit or 64-bit version of Linux. This information is vital when installing new software or troubleshooting hardware compatibility issues.
The #nproc Command
The `#nproc` command prints the number of processing units available to the current process. This could be useful when you are doing resource-intensive tasks and need to know how many processors are available.
In conclusion, mastering these Linux commands: `#date`, `#uname`, `#hostname`, `#hostid`, `#arch`, and `#nproc` will significantly enhance your efficiency and productivity in managing and understanding your Linux system.
#LinuxCommands, #OpenSource, #CommandLine, #SystemManagement, #Kernel, #Networking, #Unix, #HardwareInfo, #SoftwareInstallation, #ResourceManagement