--To--

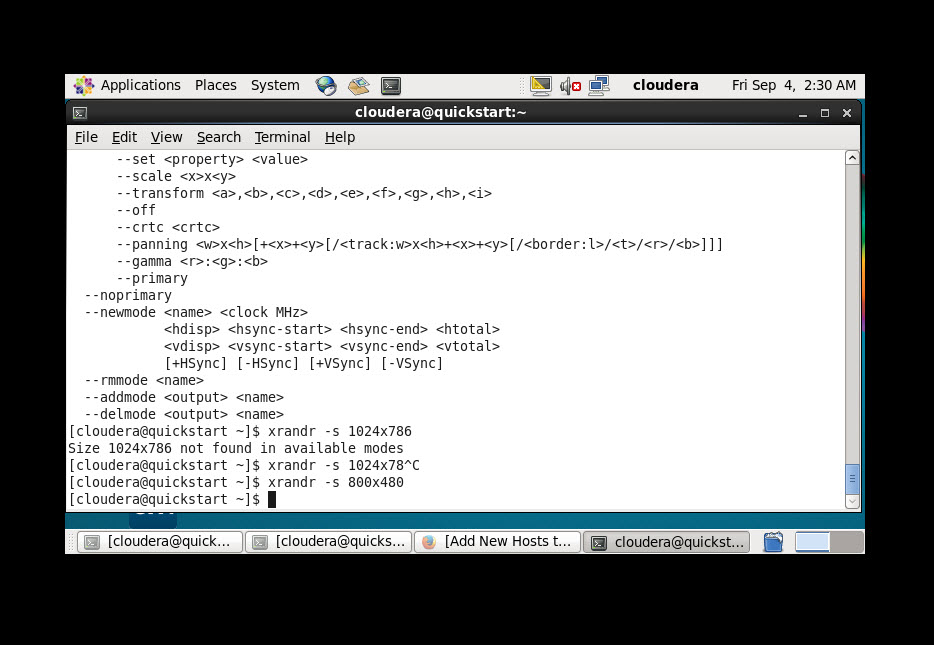
Change desktop screen size using terminal linux inside VM
xrandr -s 1440x900
xrandr -s <Resolution which you want to change>
you can use
xrandr --verbose
option to get the available screen resolution available.
Option with xrandr :
 |
RDBMS
|
Map-Reduce
|
|
Scalability
|
Scale UP
|
Scale Out
|
|
Data
Size
|
GB
|
PB and more
|
|
Read/Write
|
Batch and Interactive
|
Batch
|
|
Update
Type
|
Write many Read many
|
Write once Read many
|
|
Integrity
|
High
|
Low
|
|
Structure
|
Structural data/ Schema first Write later
|
Non Structural data/ Write first Schema later
|
|
Query
|
SQL
|
No SQL and SQL support too with add on tools
|
|
Response
time
|
Faster for Less data/ slow once size increases
|
Faster for more data in comparison
|
|
Note:
Slowly with the new sub projects being developed for Hadoop this gap is being
filled up as people are developing an abstract layer on top of Map-Reduce and
YARN frameworks which takes SQL and in turn convert it to Map-Reduce/Yarn.
|
||
 |
| Hadoop Data Balancing |
#Linux Commands Unveiled: #date, #uname, #hostname, #hostid, #arch, #nproc Linux is an open-source operating system that is loved by millio...